글쓴이: ryaniz
로컬 LLM과 클라우드 AI를 결합한 하이브리드 개인 비서 개발기 (MindSprout 1편)
1. 서론: 로컬 LLM과 클라우드 AI사이의 딜레마
최근 ChatGPT, Claude, Gemini와 같은 상용 대형 언어 모델(LLM)이 비약적으로 발전하면서, 일상적인 메모나 일정을 AI를 통해 정리하는 워크플로우를 도입하는 개발자가 늘고 있습니다. 하지만 이러한 상용 클라우드 기반 API를 개인적인 공간에 전면적으로 적용할 때 한 가지 큰 장벽을 만나게 됩니다. 바로 개인 정보 및 데이터 보안 우려입니다.
은행 계좌 정보, 사이트 비밀번호, 학생들의 성적이나 상담 일지, 기업의 대외비 정보 등 외부 서버에 전송되어서는 안 되는 민감한 정보들을 인공지능 비서에게 맡겨 처리하고 싶을 때, 우리는 다음과 같은 선택의 기로에 서게 됩니다.
- 상용 AI API 전면 사용: 추론 속도와 정합성은 훌륭하지만, 중요 개인 정보가 언제든 외부 학습 데이터로 오염되거나 유출될 위험이 상존합니다.
- 로컬 LLM (Ollama 등) 전면 사용: 데이터가 로컬 망을 절대 벗어나지 않아 보안은 완벽하지만, 제한된 로컬 하드웨어 리소스 탓에 대용량 컨텍스트 추론이나 대량의 지식을 빠르게 가공하는 데 한계가 있으며, 비용 효율성이 떨어집니다.
MindSprout Co-pilot 프로젝트는 바로 이 질문에서 시작되었습니다.
“민감한 정보는 로컬 망 내부에서 로컬 LLM으로 안전하게 차단하여 처리하고, 일반적인 공개 정보는 비용 효율적이고 강력한 클라우드 API를 이용해 스마트하게 처리하는 하이브리드 비서를 직접 구현해 보면 어떨까?”
본 포스팅에서는 이를 해결하기 위해 구축한 하이브리드 보안 라우팅(Hybrid Security Ingestion) 아키텍처와 이를 Next.js 16 및 Supabase 환경에 이식한 설계기를 상세히 공유하고자 합니다.
2. 핵심 컨셉: 하이브리드 보안 라우팅 (Hybrid Security Ingestion)
MindSprout의 데이터 파이프라인의 핵심은 데이터가 인입되는 첫 번째 관문에서 보안성 여부를 엄격히 판단하고, AI 모델의 경로를 다르게 결정하는 것입니다.
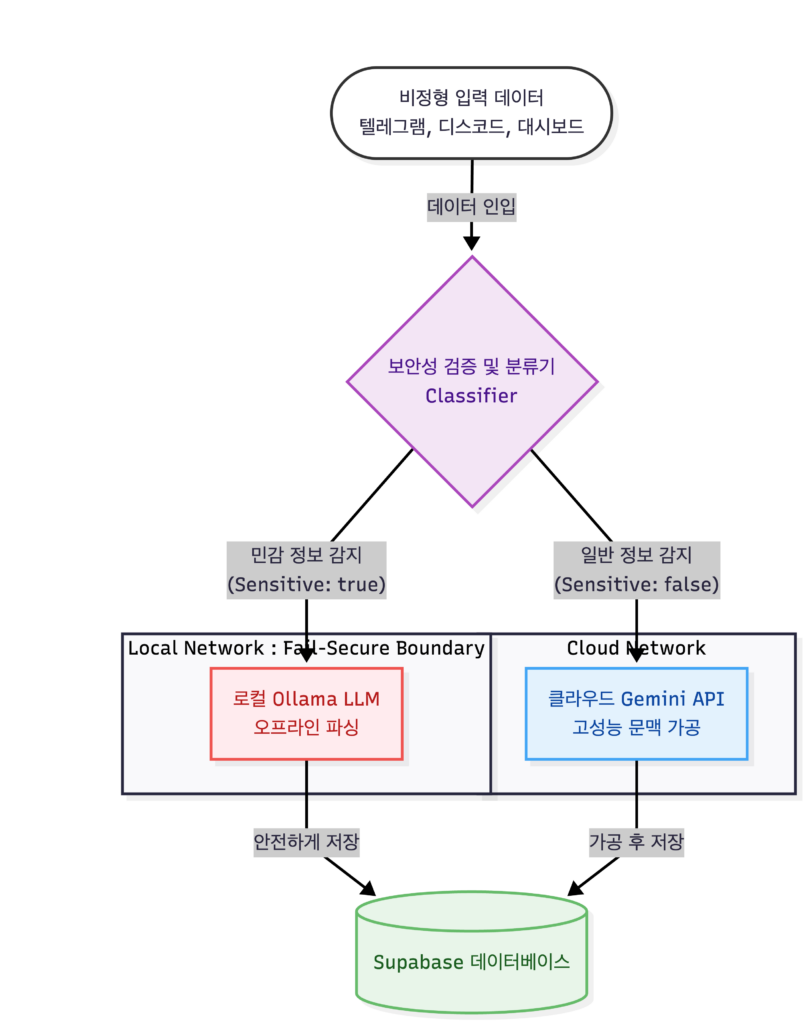
*(스크린 리더 및 검색엔진 보조용 구조도)*
[비정형 입력 데이터 (텍스트/음성)]
│
▼
┌─────────────────────────────────┐
│ 보안성 검증 및 분류기 (Classifier) │
└─────────────────────────────────┘
│
├─► [민감 정보 감지 (Sensitive: true)]
│ │
│ ▼
│ ┌──────────────┐
│ │ 로컬 Ollama (오프라인 처리) │ ──► [안전하게 Supabase에 저장]
│ └──────────────┘
│
└─► [일반 정보 감지 (Sensitive: false)]
│
▼
┌──────────────┐
│ 클라우드 Gemini API (온라인) │ ──► [가공 후 Supabase에 저장]
└──────────────┘2.1. 데이터 인입 및 분류
텔레그램, 디스코드, 웹 대시보드 등 다양한 경로로 가공되지 않은 비정형 텍스트나 음성이 들어옵니다. 시스템은 데이터베이스에 해당 레코드를 삽입하기 전 혹은 외부 API로 페이로드를 전달하기 전, 로컬 보안 등급 분류기(Classifier)를 가장 먼저 거치게 만듭니다.
2.2. 로컬 및 클라우드 경로
분류 결과에 따라 데이터의 이동 경로가 완전히 달라집니다. 기밀 키워드나 명시적인 프라이빗 태그가 감지되면 로컬 PC에 띄워진 Ollama(오프라인 로컬 LLM)만으로 텍스트를 구조화합니다. 반대로 민감 데이터가 아닌 경우에는 추론 능력이 뛰어나고 비용 효율적인 Gemini API로 패싱하여 풍부한 문맥 처리 결과를 확보합니다.
2.3. Fail-Secure 정책
이 파이프라인에서 가장 중요한 핵심은 외부 네트워크 통신을 완전히 차단하는 Fail-Secure Boundary 정책입니다. 만약 민감 정보로 분류되었는데 로컬 LLM이 다운되거나 오류가 발생하더라도, 편의성을 위해 클라우드로 우회(Fallback)하지 않고 즉시 프로세스를 차단하여 데이터 유출을 원천 봉쇄합니다.
3. 핵심 코드 구현 살펴보기: Classifier & Routing Engine
이러한 정책을 실제로 작동하게 만들기 위해 TypeScript 환경에서 구현한 구조를 살펴보겠습니다.
3.1. 민감도 분류기 (src/features/router/classifier.ts)
가장 먼저 인입되는 텍스트를 검증하는 모듈입니다. 정규화된 텍스트 스캔 방식을 채택하였으며, 사용자가 직접 수동으로 프라이빗 지정을 할 수 있도록 /private 접두사나 #private 해시태그 규칙도 함께 지원합니다.
이 분류기 코드는 텍스트 중 비공개해야 하는 계좌 번호, 성적 정보, API 키 등이 포함되어 있는지를 엄격하게 걸러내어, 외부 API로의 무단 전송을 1차적으로 방지합니다.
💡 현재 분류기(Classifier)의 한계와 고도화 계획 (Next Step)
현재의 SENSITIVE_KEYWORDS 배열을 순회하는 단순 문자열 매칭 방식은 직관적이고 처리 속도가 매우 빠르다는 장점이 있습니다. 하지만 사용자가 ‘비밀 번호’처럼 띄어쓰기를 다르게 하거나 ‘계좌번호’를 ‘계좌 번호’로 오타를 낼 경우 필터링 망을 빠져나갈 수 있는(False Negative) 한계가 존재합니다.
이를 보완하기 위해 향후 정규표현식(Regex)을 도입하여 패턴 매칭을 정교화하고, 장기적으로는 아주 가벼운 로컬 NLP(자연어 처리) 분류 모델을 파이프라인 앞단에 추가하여 문맥상 형태가 조금 다르더라도 유사어와 은어까지 완벽하게 잡아내도록 시스템을 고도화할 예정입니다.
3.2. 라우팅 엔진 (src/features/router/engine.ts)
분류기의 판정 결과에 따라 로컬 Ollama 모델과 클라우드 Gemini API 서비스로 실질적인 분기를 진행하는 라우팅 엔진입니다.
여기서 가장 중요한 부분은 Fail-Secure Boundary 설계입니다. 만약 로컬 서버에 띄워둔 Ollama 엔진의 리소스 한계나 네트워크 오류로 응답을 얻어오지 못했을 때, 일반적인 어플리케이션은 사용자 편의를 위해 클라우드 모델로 백업 호출(Fallback)을 수행하도록 설계하곤 합니다. 하지만 보안 중심 아키텍처에서는 그것이 치명적인 보안 구멍이 됩니다.
따라서 MindSprout는 로컬 파싱이 실패할 경우 처리를 중단하고 에러를 상위로 던짐으로써 기밀 정보의 외부 유출 가능성을 절대 차단하도록 설계하였습니다.
4. 기술 스택 결정 배경 및 개발 트러블슈팅
본 프로젝트를 진행하며 최신 기술 스택을 도입하였고, 그 과정에서 흥미로운 난관들을 마주했습니다.
최신 Next.js 16.2.6 (App Router) 및 React 19.2.4 채택
SEO와 초기 로딩 속도 최적화를 위해 최신 Next.js의 App Router 아키텍처를 도입하였습니다. 하지만 React 19와 Next.js 16 버전은 기존 13~14 버전 대비 비동기 파라미터 제어나 메타데이터 가공에서 몇 가지 파괴적 변경사항(Breaking Changes)을 포함하고 있습니다. 이를 해결하기 위해 공식 문서를 기반으로 API 라우트와 서버/클라이언트 경계를 명확하게 구분하여 예기치 못한 빌드 타임 에러를 방지했습니다.
로컬 LLM 환경의 성능과 리소스 최적화
로컬 기기에서 Ollama를 활용해 JSON 형태의 구조화된 포맷을 강제하는 프롬프트를 보낼 때, 로컬 모델(Llama 3 등)은 때때로 프롬프트 규칙을 어기고 불필요한 설명을 덧붙이는 현상이 발생했습니다. 이를 극복하기 위해 SYSTEM_PROMPT에 원시 JSON만 출력하고 마크다운 코드 블록(```json) 조차 붙이지 말라는 엄격한 제약 조건을 동반하여 프롬프트 품질을 유지했습니다.
5. 결론 및 향후 연재 예고
결과적으로, MindSprout Co-pilot은 상용 LLM의 우수한 품질과 로컬 LLM의 안전한 프라이버시 보호 장점을 모두 갖춘 하이브리드 개인 비서 솔루션으로 자리를 잡아가고 있습니다. 현재 이 분류 엔진을 거친 데이터들은 Supabase의 칸반(Kanban) 보드 테이블 및 지식 아카이브와 긴밀하게 연동되어, 대시보드 상에서 편리하게 모니터링할 수 있는 상태입니다.
다음 포스팅인 2편에서는 Next.js와 Supabase 데이터베이스 간의 실시간 마이그레이션 전략, 그리고 Ollama API를 로컬 서비스 수준에서 어떻게 경량화하여 연동했는지 코드와 함께 더 깊이 다루어 보겠습니다.
피드백이나 질문은 언제든지 아래 댓글로 환영합니다. 긴 글 읽어주셔서 감사합니다.